Member-only story
RAG Evaluation with LLM-as-a-Judge + Synthetic Dataset Creation
Forget Custom Human QA Pairs
RAG (Retrievel-Augmented Generation) acts as an internal query tool that utilizes LLMs to retrieve information from a “knowledge” base.
Evaluating an LLM is simple: during training, LLMs utilize human feedback (RLHF) to assign weights to particular model outputs based on categories, such as semantics, toxicity, and hostility. The LLM adjusts and creates more alike outputs.
With RAG-based systems, however, the success of such systems depends on the LLM’s ability to extract product-useful information. Therefore, the evaluation of RAG cannot depend on benchmarks or semantics.
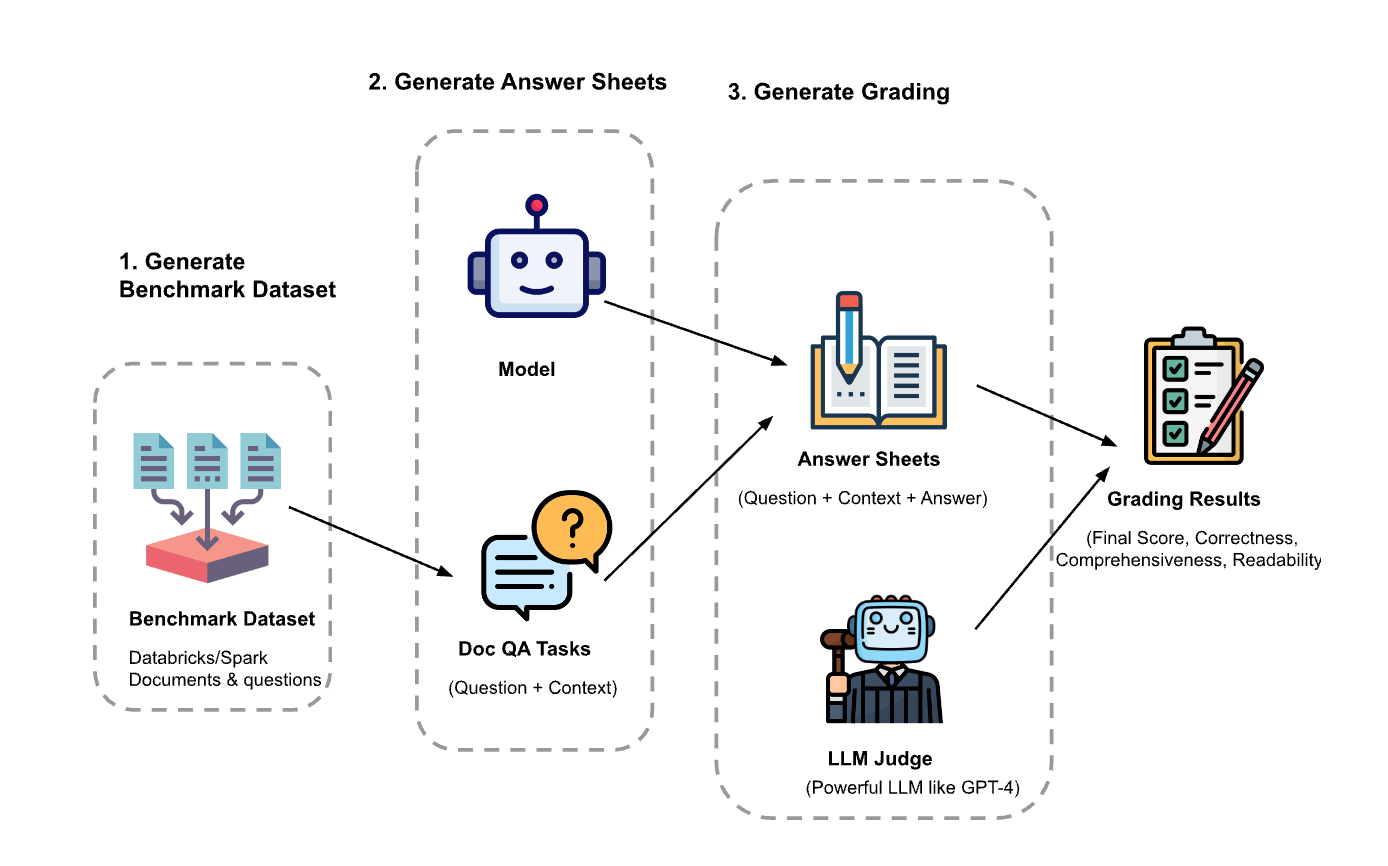
Solution? Custom evaluation dataset + LLM-as-a-judge.
➡️ It turns out, we can use LLMs to help us all along the way!
Here’s What You’ll Learn in THIS Article:
- System Design of a Complex RAG System
- How to Implement an LLM-as-a-Judge RAG: Complete Code Walkthrough
1 — Let’s Start: System Design of a Complex RAG System
RAG is a popular approach to addressing the issue of a powerful LLM not being aware of specific content due to said…

